
Have you ever thought about how to find all pages on a domain? or how to get all url of website or how many pages does my website have? You may think, why do I bother about old pages of the website? Even if there are pages in the background, what harm would they do to my site? The simple answer to this question is that every page of your website will be considered when ranking your site in organic searches. Moreover, the page that does not contribute to your growth is consuming some server space and bandwidth.
In this article, we will explain how to check all pages of a website and how to find hidden website pages. So there is much to cover; let’s dive in!
Why You Should Know How To Search All Pages of a Website?
As the number of pages grows, the cost to manage the pages also goes up, which eventually contributes to the overall expense. The pages which are active in the background are wasting your money. Therefore, it is essential to find every page on a website.
Another important factor that you should know about the hidden page is that there will be a situation where people are visiting your website with a blank page. The page would have a script error. Visitors will leave immediately if they do not find the relevant content. It will have a bad experience for the visitors. You may be losing potential buyers on your website.
Such pages would have a high bounce rate. Google will note down the user activities and pages with a high bounce rate or low visit time. Such pages are pushed down from the Google ranking. That’s why you must know how to find all pages on a website.

Websites are developed to serve the customers / Visitors. Pages of your website work as the entry gate of the website. Your website may have relevant pages with high-quality content, but these pages are not visible to potential customers or visitors. The search engines will not crawl them. Search engines would never know what website pages list in the background without crawling.
As a result, it will never index on the search engine. Your target users will never get to see these pages if they are not indexed. They will be hidden from all the time-consuming web resources. Crawling and indexing is a continuous search engine that runs on a website.
Without knowing how to find new pages on a website, you will never know what to index or hide. Once you have the list of the website pages, you can submit them in the XML sitemap. Instruct the search engine to crawl and index the listed pages in the search.
To find out the keyword in domain name SEO impacts, check this article out!
How To Find Hidden Website Pages?
Hidden pages are those that are not accessible via a menu or navigation. Though visitors may view them, primarily through anchor text or inbound links, they can be challenging to find.
Pages that fall into the category section are also likely to be hidden pages in the admin panel. The search engine may never access them, as they do not access information stored in databases.
Hidden pages can also result from pages never added to the site’s sitemap but existing on the server.
One of the common questions that come to mind is how to see hidden pages on a website? There are several reasons why your website pages might be hidden from you and search engines. When you build a website using the popular CMS, the software produces many files that interact with each other to exchange information from one page to another.

These pages are designed to fetch the content from the database. Various files such as temporary files, backup files, duplicate content files, error reporting files, etc., are automatically created on the server. These pages remain in a separate folder on the web.
As s owner of the website, you may not have the technical knowledge to find these folders on the server or detect what errors the script has caused. As a result, the created folders and pages will be there in the background, which is not visible from the site’s front end. So it is vital to learn how to find all pages on a website!
Here are two ways that you can use to find hidden website pages:
1. Use Robots.txt Files
Website owners can hide their pages from indexing by adding the addresses of those pages to a text file named Robots.txt.
To find these hidden pages, type [domain name]/robots.txt into the location line of the browser and enter. Then replace the [domain name] with your site address.
Entries with the preface “nofollow” or “disallow” show website parts that are not accessible via a search engine. Deny rules in robots.txt discourage search engines from crawling certain website pages and directories, and major search engines usually respect such rules. But in some cases, some of them don’t! If you want to restrict access to certain contents on your website, you may use .htaccess or IP and Domain restrictions in Apache webserver or IIS.
If you are willing to know what does parked domain mean , this article can help you!
2. Find Them Yourself Manually
For example, as a website owner who sells products via his website, You can manually copy and paste your other product URL into your browser and edit it appropriately. If the browser does not show the page you are looking for; then it is hidden.
If you have no idea of which pages could be hidden, you can find them by organizing your website into directories, and then you can add your domain name/folder name to your site’s browser and find the way through the pages and subdirectories. After seeing the pages, you should add them to your sitemap and have a crawl request.
3.Using a Log
You can refer to a log to see the hidden pages on your site. A log is kept of all visitors to your site, the pages they visit, and how long they remain on those pages. With this log, which you can receive from your host provider or by logging into your cPanel in ‘raw log files,’ you can track your site activity. The pages that are never visited or have the highest drop-off rates may be hidden or dead-end pages.
4.Using a Sitemap file
Whether you have a sitemap or use a sitemap generator to create one, you can use it to find hidden your site pages. To use a generator, just enter your domain name and the sitemap will be created for you.
If you aim to find the answer to the question ” is a subdomain a separate website “, check this article out!
What Type of Pages You Would Find on Your Website?
1) Error Pages

Modern CMS and wide verities of the template files produce the error message when the software cannot find the content on the server. The script error automatically creates the page in the background. Some error pages would have the error message, and some will be entirely blank. The error pages need to be identified as early as possible to fix them.
2) Orphan Page

The orphan pages are the pages with no link from other pages of your site. Due to this fact, they are not discoverable while crawling your website by a search engine. Even the visitor who visits your site would never be able to reach the Orphan pages. The search engine crawler would never get to know such a page exists. So, you need to know how to show all website pages.
It will not appear in the search engine result until it is linked to some adequate pages. As a consequence, your page will never get visitors. Your website pages must link to one another or add them to the sitemap so that the search engine knows that there are pages in the background that need to be crawled and knows about checking all pages on a website.
Examples of Orphan pages are typo errors, duplicate pages, syntax errors, expired content, pages created for A/B Testing, promotional landing pages, pages created during the site’s migration, etc.
3) Dead-End Pages
Dead-end pages are one-way directional pages. Once the user reaches the end page, they have only one choice, to close the page and move to another site or go to the previous page. The dead-end page will not have any call to action or link to the other pages. Nothing is found on such pages.
It means you are losing your traffic from this page. People will be confused when they reach the dead-end page. They wonder what next to do on the site. Eventually, they will pass the page and close the window. Dead-end pages impact the search engine ranking as your users leave your site. You should know about these pages and take some action to redesign them or add some information or call to action so that people will stay on the website longer.
If you aim to find the answer to the question exact match keyword penalty, check this article out!
How To Find All Pages on a Domain?

In this section, we will introduce some practical ways to help you figure out how to view all website pages:
1- Using Your Sitemap File
The first way to get all website pages is to take advantage of your Sitemap. If you do not have a sitemap, a sitemap generator can help you to generate one for yourself. You need to enter your domain name, and the Sitemap will be generated for you.
You can easily find all website pages using the XML Sitemap. The XML Sitemap is the precise way to count the number of pages without much effort. You can use this method for any website because the Sitemap is accessible to all users. If you have the site URL, quickly open the Sitemap on the browser using one of the below URLs:
http://sitename.com/sitemap_index.xml – For a site having multiple Sitemaps
http://sitename.com/sitemap.xml – For a site having a single Sitemap

You may need to manually count either one by one or copy the XML to an Excel sheet and count it if the count is not shown on the Sitemap. So you can also use online Sitemap or link checker tools for this purpose when the size of the site is smaller. As you can see, using your sitemap file helps you find all pages on a domain.
If you need to know how often does domain authority update, this post can help you!
2- Find All Pages on a Website Using Your CMS
You can also search all pages on a website from the CMS, while your sitemap does not contain all the links or, your site is powered by a content management system(CMS) like WordPress. To find all pages on website, using a plugin like Export All URLs can help.

3- You Can Take Advantage of a Log
At this level, to find all pages of website, using a log can be efficient. Keep in mind that a log of all the pages served to visitors also comes in handy. You can log in to your cPanel, then find “raw log files.” On the other hand, you can request your hosting provider to share it. After that, you get to see the most frequently visited pages, the never visited pages, and those with the highest drop-off rates.
4- Using Google Analytics
Crawlers cannot find orphan pages, so this is where Google Analytics comes on the scene. This method only works for the websites linked to the owner’s Google Analytics account from the beginning.
Steps for finding all pages via Google Analytics:
- Step 1: log in to your Google Analytics account.
- Step 2: go to “Behavior,” “site content,” and at last, “all pages”
- Here you can see the pages that are hard to find through your site, so they have a small number of page views.
- Step 3: Click on “pageviews” and sort the page URLs from least to most pageviews. Here you can see the least visited pages at the top.
- *try to set the time range before your website’s connection to Google Analytics. It would help if you watched out for the data sampling issues.
- Step 4: now it’s time to scroll down. Try to find pages with way more visits than orphan pages and stop at the first one of them. All of the pages at the top of this point are orphan pages. export the data into a .csv file.
- Step 5: the data we exported from Google Analytics is not in URL format. We need to make a spreadsheet with three columns to fix this problem. The “A” column (the first one on the left) should be your SE Ranking. The “B” column (the middle one) should be your home page URLs, and the “C” column (the last one on the right) should be your Google Analytics data.
- Step 6: use the “concatenate” function to mix the values of columns “B” and “C” in column “D.” now drag the box down to have a complete list of URLs. This new column would be your Google Analytics URLs.
- Step 7: here are two ways to do this step: you can manually look for the missed pages by comparing the “SE Ranking” column with column “D.” this will take a lot of time!
Or
You can use the “match” function to see if every value in column “D” is present in the “SE Ranking” or not. To do this, click on the first box of the “E” column and enter the function, then drag the box down to the last value.
Values with no match are shown by “#N/A” in the match column (E). These values are your orphan pages. Now you can insert them into a new spreadsheet.
Note: You can quickly sort your data by clicking on the column first and then choosing “data” in the top left of the window.

5) Using Google Search Query
Type www.abc.com into a Google search query. Then replace “abc” with your domain name. The search results include all the URLs crawled and indexed by Google. Afterward, you can copy and paste all of them onto an excel spreadsheet.
Now, what can you do with your URL list?
a) You can manually compare them with log data.
- By doing this, you can see all website pages without having any traffic or those pages that seem to have high bounce rates. Then you can use tools to look for inbound and outbound links for pages that could be an orphan or dead end.
- Another way for doing this is to download all of your URLs and your logs as a .xlsx (excel) file. Place them side by side and use excel’s “remove duplicates” option. Follow the instructions step by step. In the end, you will only have orphan and dead-end pages.
- The third way to get all website pages is by copying your URLs and logging the list onto Google sheets. Then you can use the “VLOOKUP” formula to find out which one of your URLs is not on your log list. These missing pages are orphan ones. Make sure to put your log data on the first column (left side).
b) You can use site crawling tools by loading your URL list onto these tools and wait for them to crawl the website. Then you can copy and paste all of the URLs onto a spreadsheet and find out which ones could be orphan or dead end.
These two methods mentioned above (a & b) are easy and fast so they can save a lot of your time.
6) Using Google Search Console
Some of the pages could not be found by previous methods. These pages are only accessible to Google, so using the Google Search Console can handle this issue.
Steps of getting a list of all pages on website via Google search console:
- Step 1: Open your account and go to Coverage.
- Step 2: select “all known pages” instead of “all submitted pages” and enable you to view only valid pages. Here you will see two types of pages, submitted and indexed or indexed, not submitted in the sitemap.
- Step 3: search for pages that we could not find by previous methods. If you find any of them, check that they are set uprightly in your website’s framework.
- Step 4: select “Excluded.” This will show you the pages that were not indexed by Google and won’t appear in it. After this step, you have to do some manual work so take your time!
- Step 5: you can see lists of Excluded pages like those crawled- currently not indexed, blocked by Robots.txt, duplicate without user-selected canonical, etc. Here you can have complete access to every single page on your site. Now it is time to compare the orphan page data with the data of this list. Then, you will have a general overview of all of your website’s pages.
It is better to repeat this method once or twice a year to find all pages of a domain that might be unnoticed.
7) Use the Chrome console
Another way to find links on a page (note this method only shows links on a page, not all pages) is to use the Google Chrome console.
Just right-click inside the page or press the F12 key on the keyboard, enter the console and paste the following phrase there; you can easily find all the links inside that page:
urls = document.querySelectorAll('a'); for (url in urls) console.log(urls[url].href);
You can also run the following code to write all the links in an array
Array.from(document.querySelectorAll("a")).map(x => x.href)
8) Use ScreamingFrog
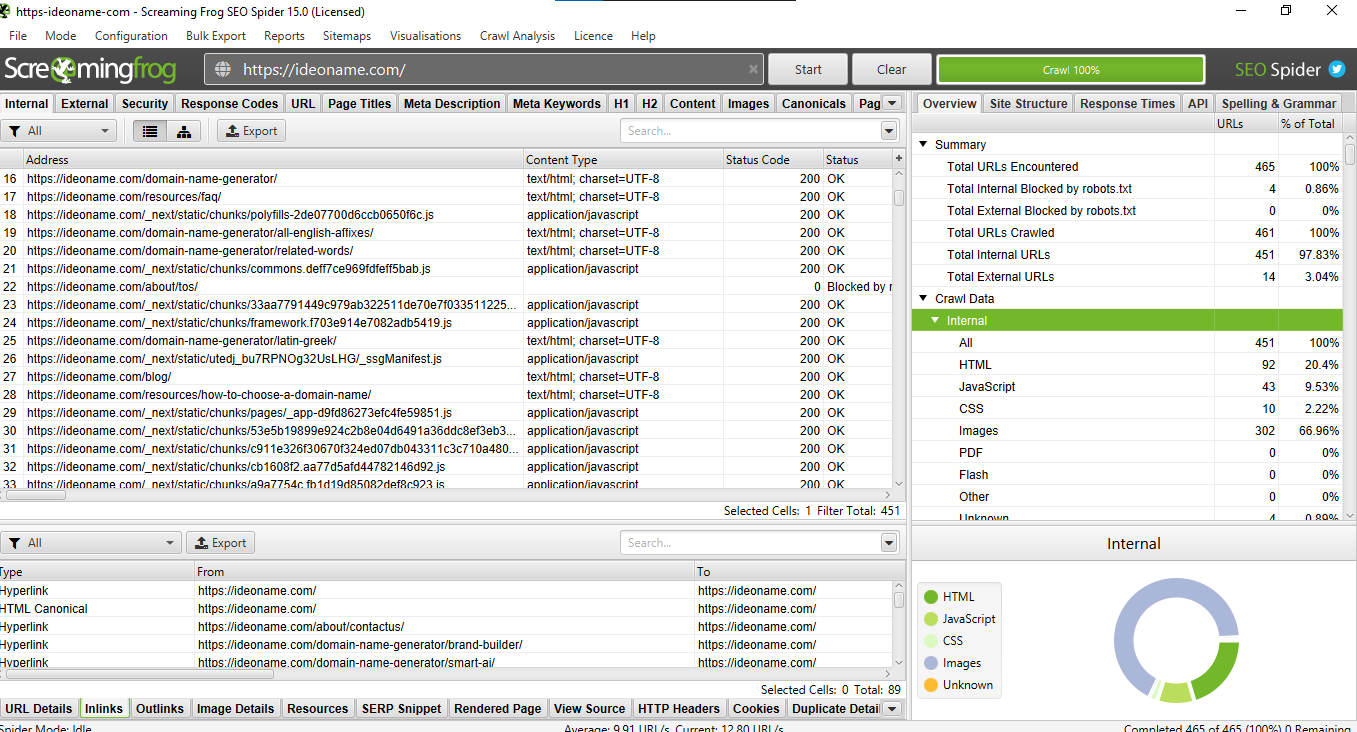
If you still have questions about “how to see all pages of a website,” Another of the best internal and technical SEO tools is accessible ScreamingFrog. You can download this program from this link. Just enter your site address and wait. This program shows you all the pages of that site with all the SEO specifications, including the title, etc., orderly.
You can also use the slider button to tell Frag Scruming what pages and files you want to show you and optimize and organize your data.
9) SE Ranking
Another tool is to find all the pages of a site that works like scrambling is SE ranking. You can enter the link of your site or others, and through the menu settings, select the items you need and wait for a while for the tool to do its job.
You can enter your Google Analytics account, search for your console, and find exciting data.
10) SEOptimer
This tool allows all pages on a website to be SEOtimer. You can start by going to “Website Crawls” and entering your website URL. Hit “Crawl”, And after a short time, it will find all the pages of your site
Frequently Asked Questions
How Do I See All the Pages on a Website?
There is a simple way that you can search all pages of a website:
- Go to the Google search bar (or address bar of your browser)
- Type “site:” followed by your domain name (site:mydomainname.com)
- Follow the domain name with a single space. Type the search phrase
- Click Enter/Return to start searching
In this case, you can utilize the way Google list all pages on a website.
What Is a Tool To Find All Webpages on a Domain?
There are different tools that you can utilize to see all pages on a domain, such as:
- Your sitemap file
- Your CMS
- Using a log
- Google Analytics
- Google search query
- Google search console
Final Words
In this article, we have studied how to find all the pages on a website or list all pages on a website and why it is critical. We have also found concepts like orphan and dead-end pages, and hidden pages. Finding all pages on a website would enable you to optimize your website better for the search engine ranking. Also, it will improve the quality of your site. Your users would love to spend more time on your site when they find relevant content with no dead-end pages.
Finding all the pages on a website would become easy when you use free tools that crawl the website and provide a comprehensive list of the available pages. Hope the article has helped you learn how to check all pages on a website.
I have reported from the pages I have on the site for a period of one month, but the report is different, although I have not added or subtracted any pages. what is the reason?
hi
I want to see all pages on a website and your article help me
tnx